In this article, I would like to talk about Process Mining and to present the proposed architectural solution for our software platform. Below are the topics covered:
- Definition of Process Mining as a tool for improving the production and management processes of an organization.
- Definition of requirements and characteristics of a Process Mining software platform.
- Definition of the domain language and business sub-domains in which the problem has been decomposed by adopting domain driven design principles.
- Presentation of the architectural solution identified.
Process Mining definition
The Process Mining originates from the combination of two different disciplines:
- Data science - that deals with the analysis, interpretation, and extraction of knowledge from data (models, trends, relationships, and meaningful information) through the use of scientific methods, algorithms, tools, and programming techniques,
- Process Science - that combines knowledge produced by information technology and knowledge extracted from management processes to understand and improve the productive and managerial processes of an organization.
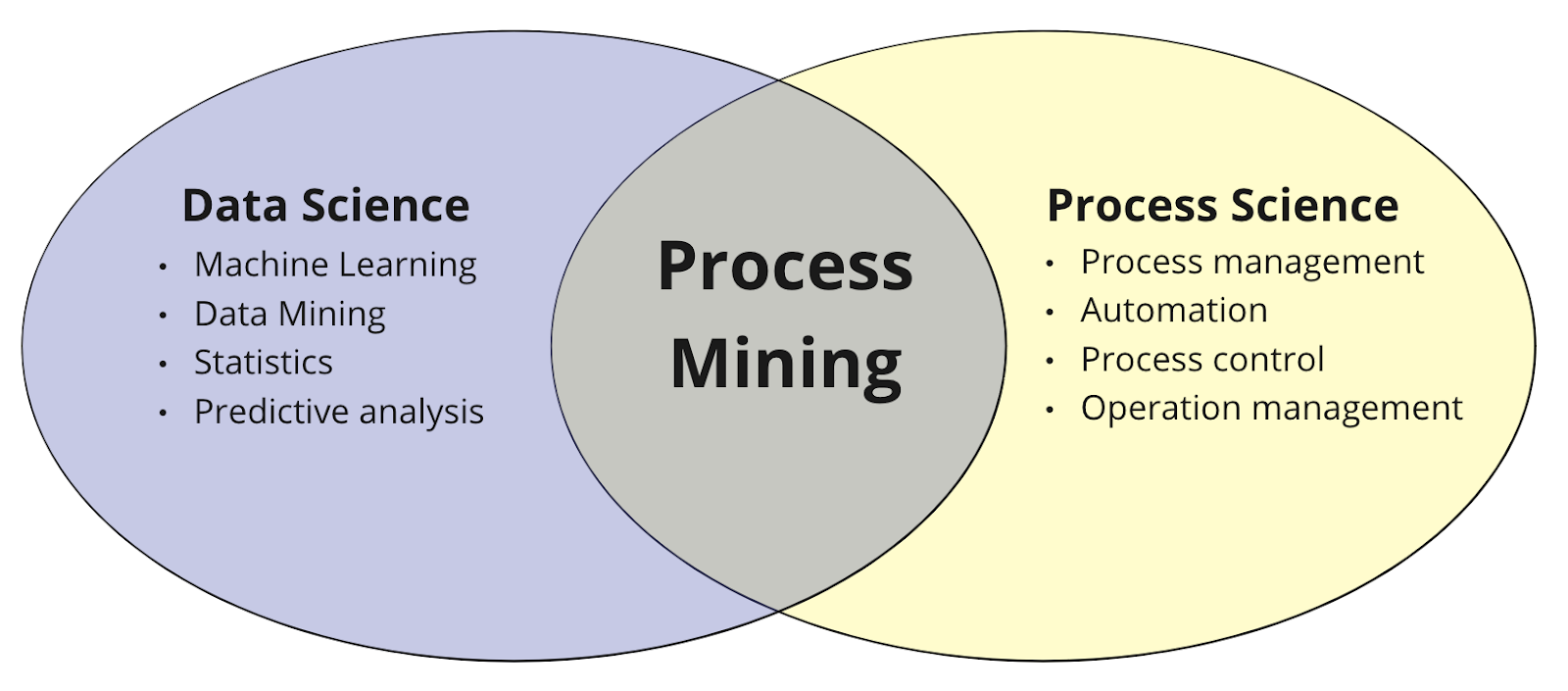
Figure 1 - What is Process mining?
Process Mining therefore is the fusion of these two disciplines and deals with the analysis and extraction of information from business process logs, applying statistical/mathematical techniques and algorithms, in order to understand and describe the processes executed within an organization.
Activities
The main activities of Process Mining include:
- Data extraction: building of process mining input data set (event log) starting from the Information System of an organization. This activity is in front of the process mining activities but is essential to standardize its inputs.
- Discovery: data extraction from process logs to identify and represent existing workflow patterns. This phase utilizes various process mining algorithms that use log data to model the ideal process model (es. Ɑ-algorithms, Inductive Miner algorithms, Heuristic Miner algorithms). The output of this phase is a discovery process model that describes the analyzed process as accurately as possible based on the collected data.
- Conformance checking: comparison of models generated during the discovery phase with real data to identify variations between the planned and actual process executions. The goal is to verify how much real processes deviate from the standard.
- Enhancement: optimization of the existing process model using additional information.
- Predictive process monitoring: use of AI models trained on log data to detect anomalies and predict the trends of production flows.
- Process simulation: use of mathematical models to simulate business processes under specific conditions with the aim of evaluating optimizations and identifying corrective actions in response to particular conditions ("what-if" scenarios).
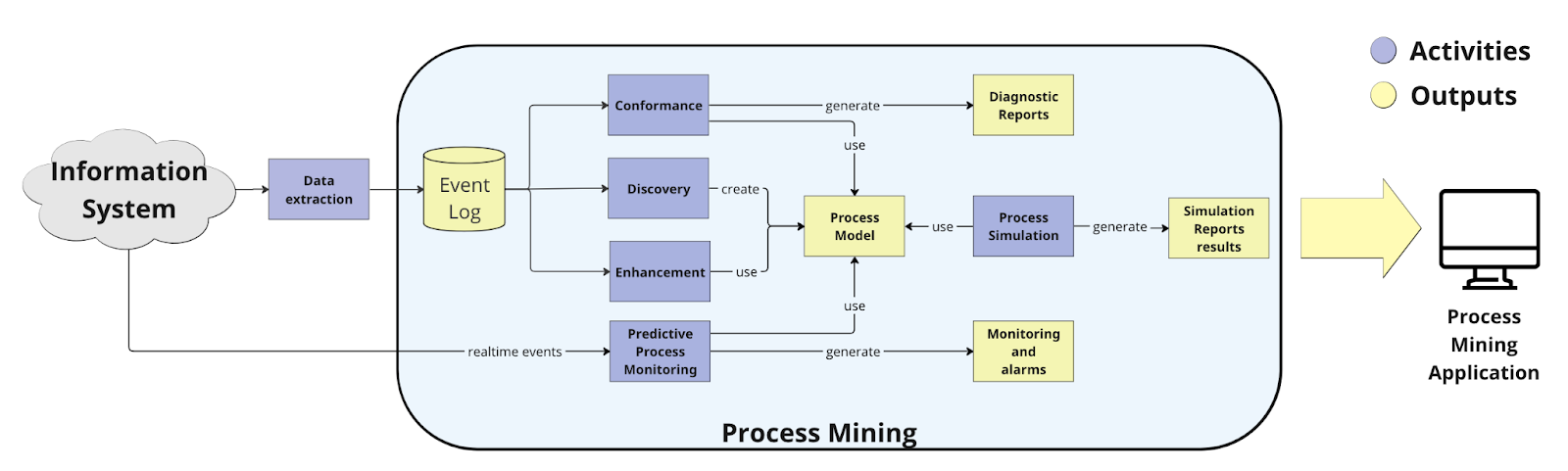
Figure 2 - Process Mining activities and outputs
Event log
The event log is the input data stream to Process Mining functionalities. It contains chronological and sequential information about each step, action, or event that occurs during the execution of business processes. Each record in the event log represents a specific instance of an activity or event and includes information such as the process instance identifier, the activity performed, the timestamp of the event, and any other relevant information.
Each instance (record) of the event log must contain the following information:
- Case ID: the unique identifier of a process instance to be analyzed (e.g., production order code).
- Timestamp: the time at which a specific activity is carried out within a process.
- Resource: the entity performing an observed activity within the process (e.g., machine, operator, specific software).
- Activity: the action performed by a resource within the analyzed business process.
- Attributes: a set of additional optional information associated with the various rows of the event log, useful for detailed analysis of events.
The event log can be saved in various formats such as CSV, XES, OCEL, and stored within a database (SQL or NoSQL depending on the requirements). Below is an excerpt from an event log regarding airline flights in CSV format.
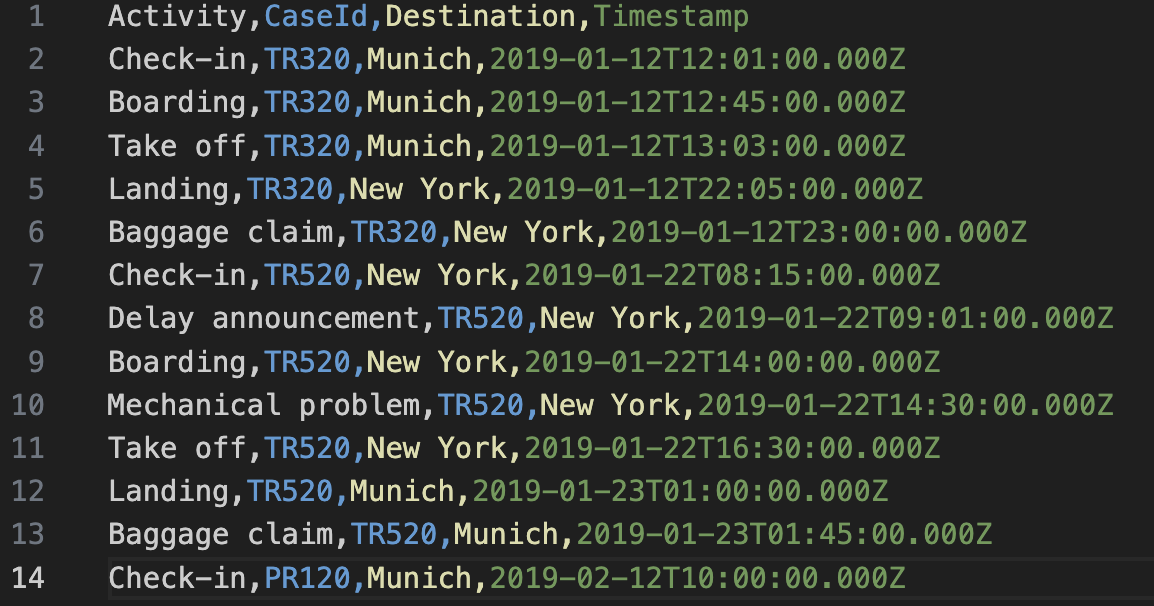
Figure 3 - CSV Event log example
Let’s proceed with some other domain terminology and concepts of Process Mining.
Process model
The Process model is a visual representation of a workflow, produced by discovery and enhancement algorithms from event log data. Process models offer quantitative, objective illustrations of business processes. These models contain workflow data, including activities, resources that made each activity, paths taken within the workflow, timelines of each step, success rates and more.
There are different representations of the process model. For example:
From a process model we can extract information like duration of events (lead time), analyze the frequency of events or activities, identify bottlenecks of the process described.
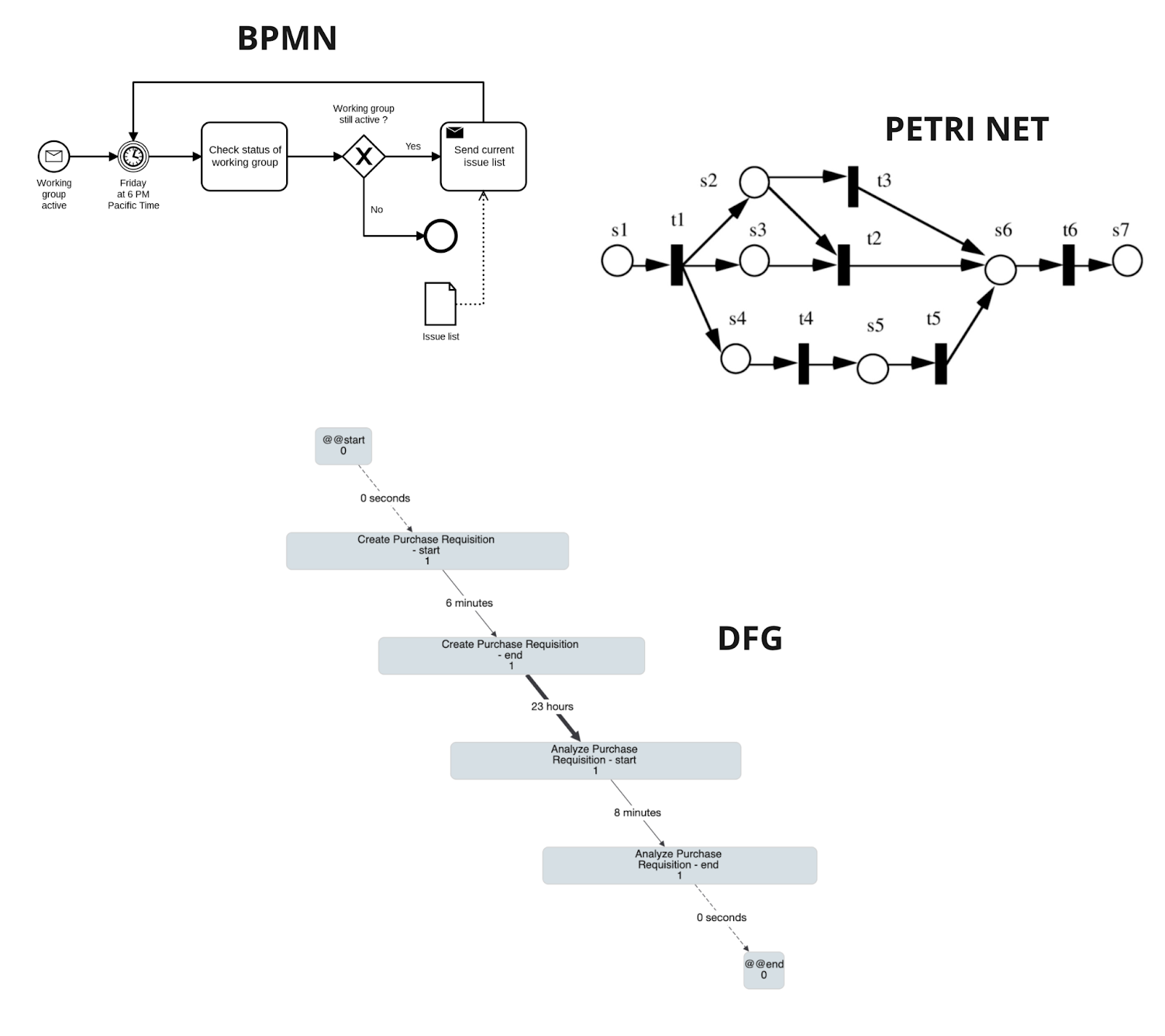
Figure 4 - Process model graphs
Lead time
Lead Time is the measure of the duration of the process or its part. Typically process mining operation returns average, median, standard deviation, maximum, and minimum values calculated on a portion of data extracted from the event log.
Variants
Variants represent different alternative paths that constitute the process model. In the description of a process, it can be useful, for example, to verify how many case IDs (analyzed instances) belong to a particular variant for a better understanding of the analyzed process.
Business Requirements
The platform has to cover a set of functional requirements to ensure in-depth and effective analysis of business processes. Below are the main requirements:
- Realization of a configurable and flexible platform that allows analyzing information and processes from different application domains of different types of customers.
- Acquisition of data from client systems for the construction of event logs.
- Execution of the "discovery" process and realization of the process model.
- Graphical representation of the process model and calculation of lead time values and variants.
- Application of filters on the fields of the event log in order to produce and analyze parts of the process.
- Analysis of process variants.
- Predictive process monitoring and anomaly detection. Management of end-process prediction alarms.
- Possibility to add future functionality and visualization widgets in the field of process mining using different open-source technologies.
- Possibility to install the platform in the Cloud (PaaS or SaaS) or on-premise at a customer site.
Architectural design
Features
Starting from requirements, we extracted the main architectural feature presented in Figure 5. These features influenced our choices about services and technologies adopted for the architecture.
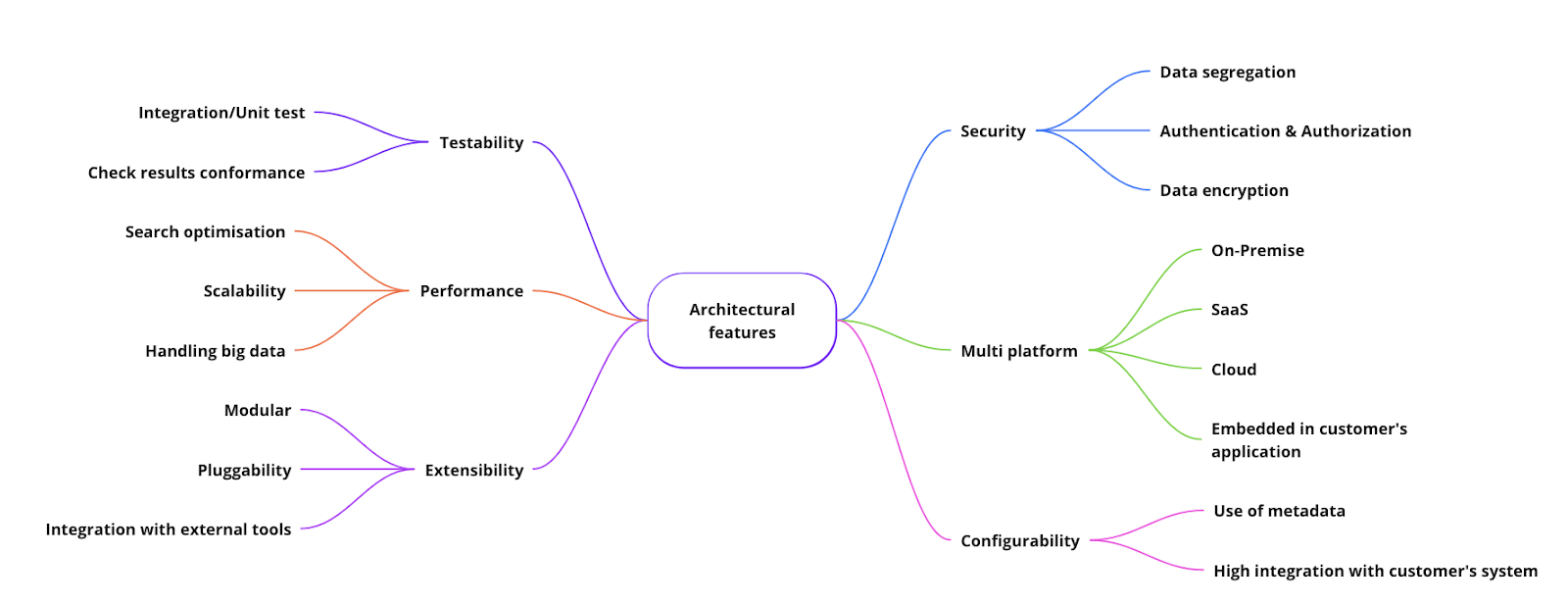
Figure 5 - Architectural features
Modeling components with DDD
In the previews paragraphs we saw that Process Mining is a complex domain with a specific language and terminology. This is the reason why we decided to adopt a Domain Driven Design (DDD) methodology. Since the complexity of the problem and the needs of extensibility and modularity for our platform, we defined differents sub-domains with different bounded context:
- Calculator - process mining operations and functions. This is the engine and the core domain of the platform.
- Orchestrator - orchestration of functionalities (managing event-log filters, ui widget and data feed, alarms from predictive subdomain, invoke operations subdomain for obtaining results).
- Authentication / Authorization - identity access management that deals with user authentication and authorization access to the platform.
- Data import - deals with data import from Information Systems and event log building and storing inside the platform.
- AI Training - preparation of the training set for predictive and simulation.
- Simulation - simulation of processes starting from the process model and introducing new variables and parameters.
- Predictive process monitoring - prediction of process delay according to training set.
- Dashboard UI - graphical user interface.
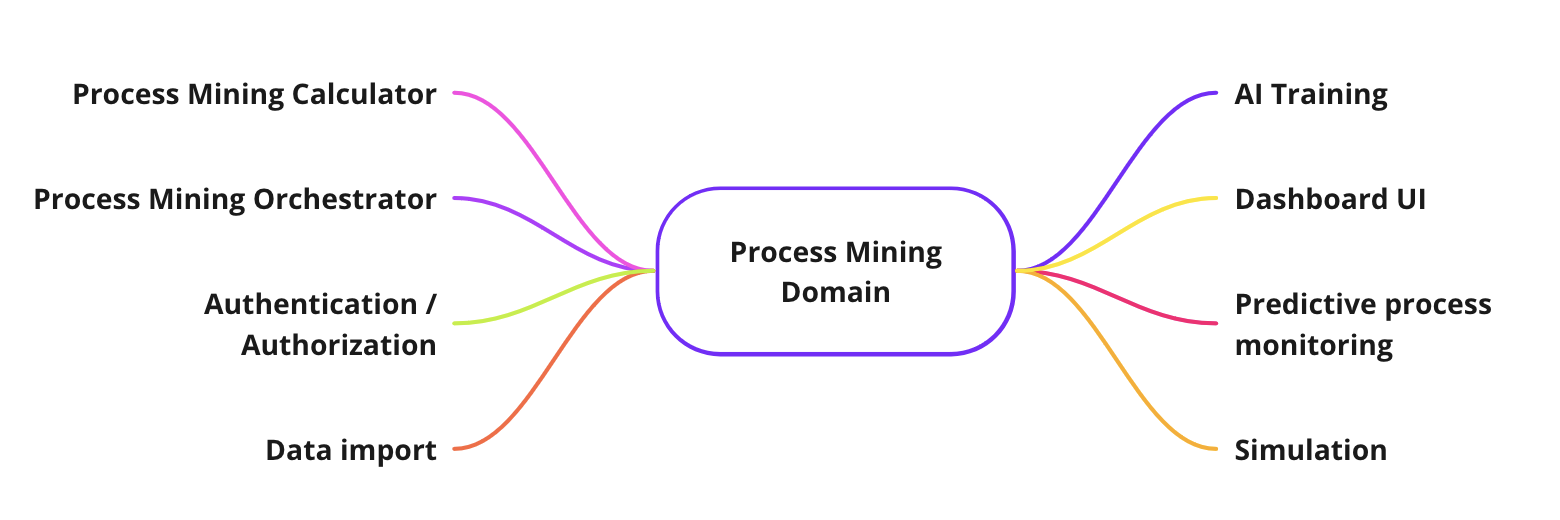
Figure 6 - Process Mining subdomains
Architectural Layers
We divided the architecture into the following layers:
- Access Layer: set of infrastructure services that govern access from the outside (internet) to the internal services of the platform. This layer is highly customizable and can change depending on the mode and infrastructure requirements of the platform deployment (on-premise,Cloud PaaS, Cloud SaaS)
- Web application: layer containing the web application of the process mining (Process Mining Dashboard).
- Application Service Layer: layer containing the application services implemented in the solution. Among the services present, only the orchestrator can be reached from the outside via authenticated Rest APIs.
- Data Import Layer: data extraction and event-log creation layer. It draws on the various client data sources containing business process information and builds the event log and various related flows that are used by the platform. This part of the architecture represents an independent and separate component from the others and can be developed with different technologies and tools.
- Data Layer: relational and non-relational databases that contain the data and configurations used by the platform.
- AI Service Layer: layer containing the modules for calculating predictive process monitoring (prediction of the time to close and process simulation)
Figure 7 shows the main services that make up the architecture of the process mining platform.
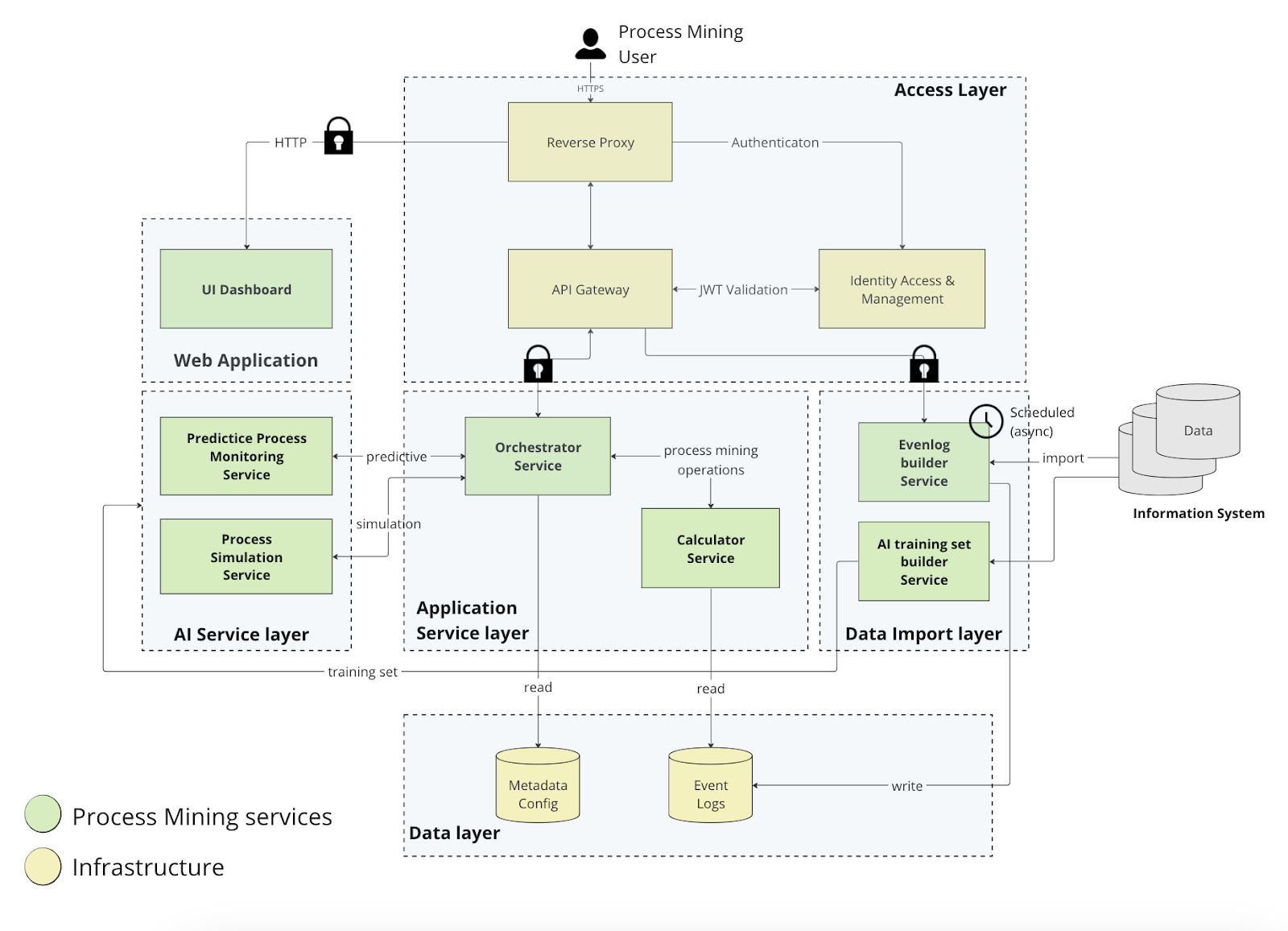
Figure 7 - Architecture layers
Microservices approach
Despite the fact that the number of sub-domains is currently not significantly high we decided do adopt a microservice architecture approach for the following reasons:
- Different languages and technologies for different sub-domains.
- Different team involved in the deployment.
- Modularity, scalability and extensibility requested by design.
We mapped each sub-domain described in the preview paragraph in different isolated services. In our design we introduced the orchestrator service that works as a coordinator from the external world and other internal services. Internal services communicate with each other mainly with REST API.
We decided to adopt a shared database approach for the activity of production of event logs since the event log builder service writes in a scheduled mode date on the database and the calculator only reads these data for process mining operations.
All developed services are encapsulated within Docker containers in order to ensure isolation and portability across different cloud and on-premise platforms.
Conclusion
In this article, we introduced the topic of Process Mining by describing the main concepts and functionalities. We then provided a high-level overview of the planned solution for the architecture of our Process Mining platform.
Technical topics were not covered, as we reserve such detailed discussions for future articles focusing on specific subjects. Stay tuned!